Secure multi-party computation (MPC) technology allows businesses to derive value from joint computations without worrying about exposing their customers’ private data. The goal of Conclave is to make these computations accessible to data scientists who have no prior knowledge of MPC – using their familiar tools, and with minimal effort.
The last few years have seen great advances in the performance of practical secure MPC frameworks. However, there remains an “accessibility gap”: most data scientists, who are familiar with relational SQL queries and big data systems like Spark or Hive, are not currently in a position to implement scalable MPC data analyses. Consider Sharemind: although it is among the fastest MPC frameworks available today, inherent scalability limitations of secure operations under MPC make it infeasible to process large volumes of data in Sharemind “out-of-the-box”. Carefully optimizing the application at hand can help improve performance, but this in turn requires considerable domain-specific knowledge in MPC.
Conclave is a prototype relational query compiler that generates hybrid cleartext-MPC execution plans for queries over data stored locally or in a Hadoop Distributed File System (HDFS) cluster. Conclave takes care to optimize the query plan so that as much work as possible runs locally at each participating party using existing data-parallel analytics frameworks like Spark (if available), and automatically manages query execution via local processing and Sharemind MPC. It makes the same security guarantees as if the entire query ran in Sharemind, and offers ways for developers to add small hints identifying public columns and partially-trusted parties that can help improve performance further.
We chose Sharemind as the first MPC backend to support in Conclave because it delivers impressive performance – in our experiments, it handily outperformed several other MPC frameworks.
What are the main challenges for Conclave? First, Conclave must automatically infer from the query what operations can run locally and in the clear at each party, and how to transform the query to pre-compute as much as possible locally without parties exchanging data. Second, Conclave must handle queries that fundamentally aren’t amenable to local pre-computation: consider, for example, a query that joins two relations held by different parties and then aggregates the result. Making such queries performant is difficult, but Conclave implements new hybrid cleartext-MPC protocols that make them orders of magnitude faster if the parties agree to selectively reveal specific columns (while continuing to hide all others).
To determine the final execution plan, Conclave applies a set of query rewrite rules. Conclave starts by assuming that the entire query will run as single monolithic MPC and then applies rewrite rules to incrementally minimize the use of secure computation. An example is the MPC pushdown step which starts at the inputs to the query and moves subsequent operators out of MPC and into local processing (this is possible for operators that do not combine rows, such as projections), or splits operators into local pre-processing and aggregate MPC steps (for instance, splitting a sum into a local per-party sum and an MPC sum of the result).
Another class of rewrite rules replaces expensive MPC operators with hybrid protocols that combine cleartext computation and MPC. These rewrite rules only apply under specific trust assumptions: Conclave allows a data analyst to specify these via column-level annotations on the input relations. An analyst can identify a semi-trusted party for a private column (with the column owner’s permission); the semi-trusted party may learn the cleartext values of the annotated column and can perform otherwise expensive steps locally, instead of under MPC. An example is the hybrid join which applies when a semi-trusted party is allowed to learn the key columns of both sides of a secure join (but no other columns). Instead of determining the rows included in the joined result obliviously, the semi-trusted party can do so locally and communicate the result securely to the other parties. This allows Conclave to execute otherwise infeasible queries in a matter of minutes.
Conclave’s optimizations enable queries on federated data sets at unprecedented scale. As a sneak-peek, we show one of the workloads we used evaluate Conclave’s performance. We benchmarked Conclave on a query computing the Herfindahl-Hirschman Index (HHI), a metric used to measure financial market concentration, i.e., how much competition exists within a given market. To simulate realistic data volumes, we leveraged a publicly accessible dataset containing several years' worth of NYC taxi trip fare information, comprising over one billion records.
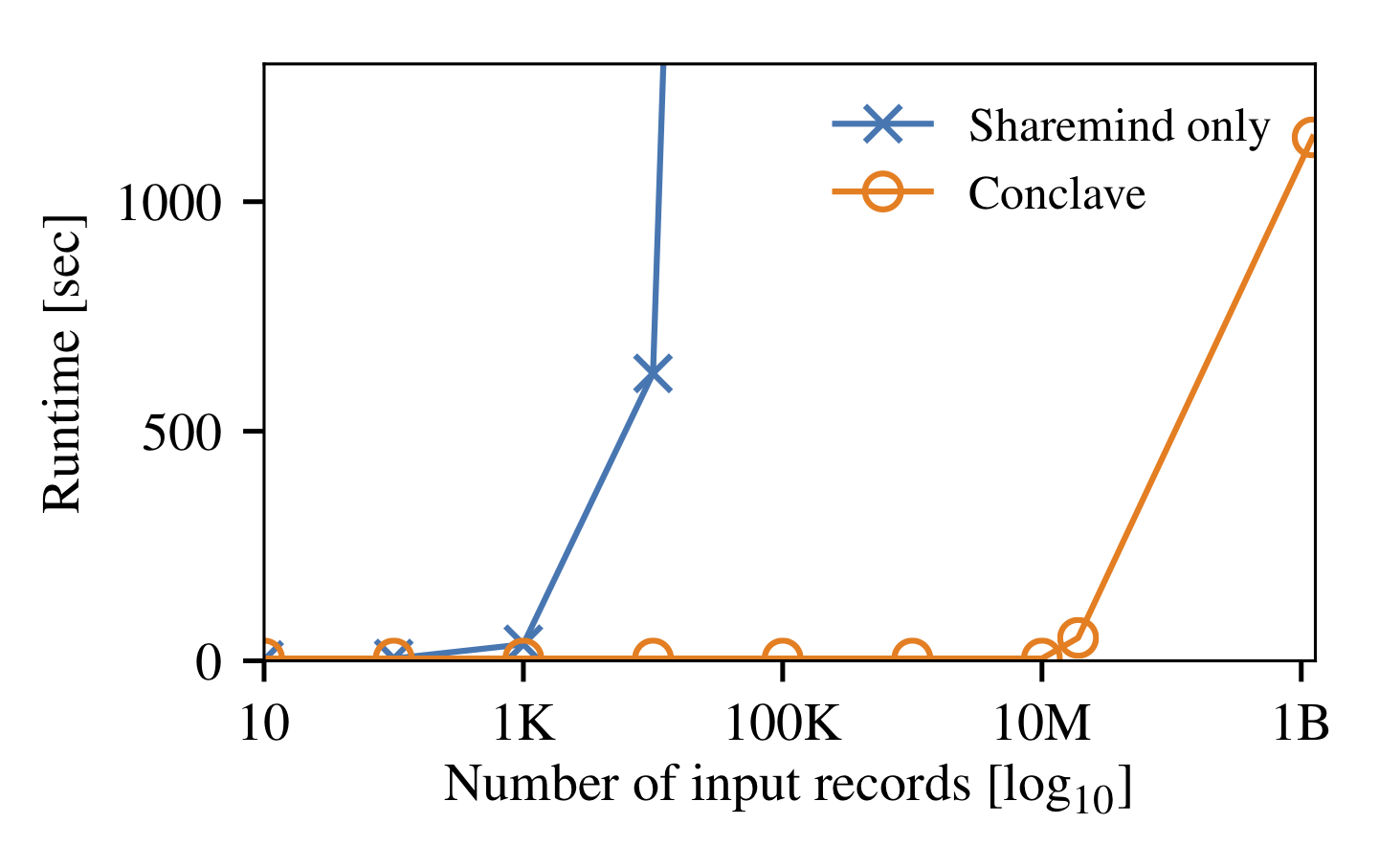
Figure 1: Conclave executes the market concentration query on a combined data set of over one billion records, while a stand-alone MPC implementation does not scale past ten thousand records.
Figure 1 shows the running time of the market concentration query using Conclave versus a baseline implementation in Sharemind, with increasing data size. Since the query contains an aggregation across the entire dataset, Conclave’s optimizations yield a five orders-of-magnitude scalability improvement over the all-MPC baseline; due to the MPC-pushdown, the parties are able to carry out most of the aggregation in their local Spark clusters, shrinking the volume of data entering MPC to only a few records. Even for the full data set of > 1B rows, the query completes in under 20 minutes.
So, does Conclave offer the ultimate “free lunch” compared to using Sharemind directly – better performance, direct integration with popular data processing systems, and automatic optimization? Not quite. To realize the performance improvements of local precomputation, Conclave must leak the size (i.e., cardinality) of intermediate relations at the local/MPC boundary (though not their content). Moreover, making joins and aggregations across parties fast requires selective annotations on the input columns. Conclave makes these choices transparent to the data scientists and their organizations’ legal oversight: at all points, Conclave clearly informs its users what information might be leaked on query execution. The choice to leak nothing and get the same guarantees as running the entire computation in a Sharemind MPC is always available – and since Conclave generates code for Sharemind, users get the same performance as with Sharemind, but with an easy-to-use relational interface and integrated with their local data processing systems.
Conclave is the result of a collaboration between the Alexandra Institute, the Hariri Institute for Computing at Boston University, and MIT CSAIL. Our current Conclave implementation is a research prototype (see conference version of the paper here: https://dl.acm.org/citation.cfm?id=3303982), and an open-source release is available here: https://github.com/multiparty/conclave. If you’re interested in more details, check out our project website. We’d love to hear what you think!

